Infer.NET user guide : Tutorials and examples
Calibrating reviews of conference submissions
In this post, we’re going to look at how to use Infer.NET to streamline the conference reviewing process. The process in a typical computer science conference involves each submission being reviewed by several reviewers of differing expertise, attention to detail, and time available. Back in March 2009, Peter Flach and Mohammed Zaki, program committee co-chairs of the ACM SIGKDD 2009 conference, asked us if we could come up with a model that could be used to calibrate the ratings against these differences. They then planned to use this model to help streamline the process for selecting the final acceptances.
Based on some previous experience with these types of models, we were able to come up with a model very rapidly, the Infer.NET code taking about a day, and some additional time for dealing with data and result handling. I will just describe the main aspects of the model and the corresponding code in this page (see the end of this post for how to get the full code). We calibrate reviewer scores using a generative probabilistic model which addresses variation in reviewer accuracy, and self-assessed differences in reviewer expertise level. The model relies on the fact that each paper has several reviewers, and each reviewer scores several papers. This enables us to disentangle (up to uncertainty) the reviewer’s reviewing standards and the quality of the papers. Similar forms of model have been used for assessing NIPS reviews, for rating the skills of Xbox Live players, and also for the Research Assessment Exercise for UK computer science, 2008. A factor graph of the model is shown below; arrows are included to show the generative flow.
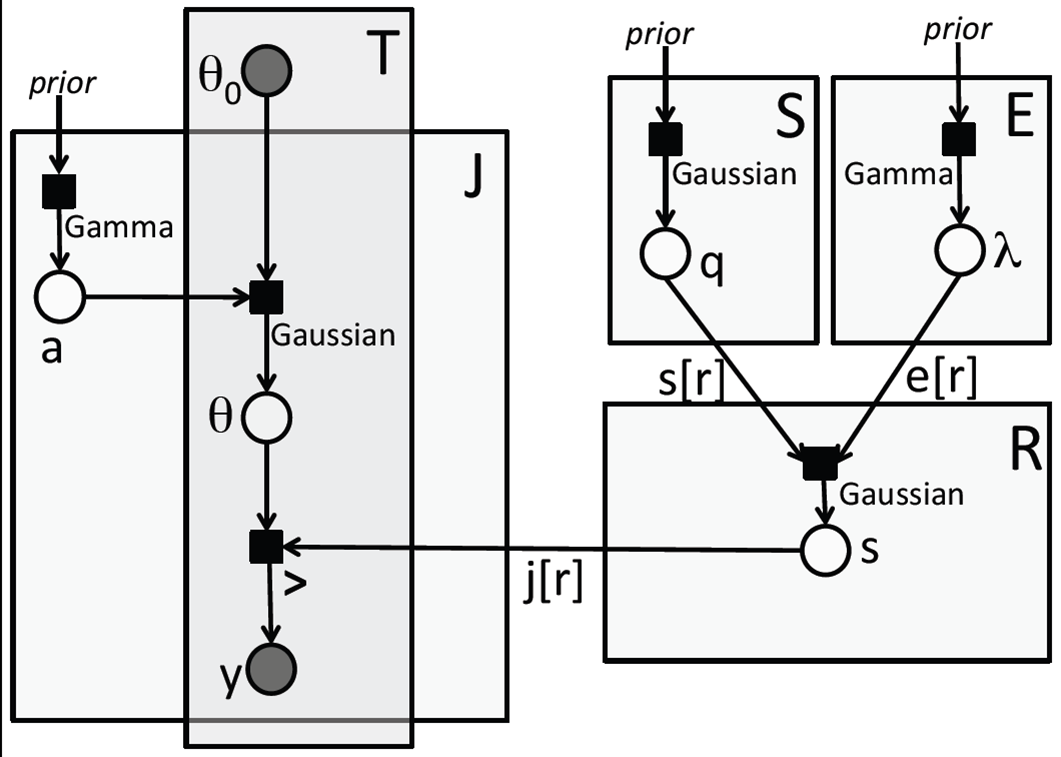
First a bit of notation. We assume that there are R reviews, S submissions, E expertise levels, and J reviewers (we use J for ‘judges’ to distinguish reviewers from reviews). These counts are shown in the top right hand corner of the corresponding plates (the rectangles in the factor graph). Recall that plates represent parts of the graphical model which are duplicated - if N is the size of a plate, there are N copies of all factors and variables within the plate. In Infer.NET, plates are represented by ranges:
Range s = new Range(S);
Range j = new Range(J);
Range r = new Range(R);
Range e = new Range(E);
There is one other range that our model uses and that is a range over T thresholds - more on that later. For each review r, there is a corresponding submission s[r], expertise level e[r], and reviewer j[r]. These dependent indices are shown on the appropriate edges in the factor graph to indicate the sparse connection topology between the review plate and the other plates. So, for example, variables/factors with index r in the review plate are only connected with factors/variables with index s[r] in the submission plate etc. This sparse information needs to be represented in the Infer.NET model, and we do this by creating integer variable arrays whose observed values are the corresponding mapping (the following code makes the assumption that expertise levels start at 1):
// Constant variable arrays
var sOf = Variable.Observed((from rev in reviews select submissionToIndex[rev.Submission]).ToArray(), r);
var jOf = Variable.Observed((from rev in reviews select reviewerToIndex[rev.Reviewer]).ToArray(), r);
var eOf = Variable.Observed((from rev in reviews select ((int)rev.Expertise - 1)).ToArray(), r);
Our generative model attempts to explain the observed data as random samples from a generative process. Let’s start describing this process by focusing attention on the top right hand area of our factor graph in the S plate. Here we suppose that there is an array of variables q (represented in the code by quality) which represent the true underlying quality of the submission. This is unobserved, and is, in fact, the main thing we want to infer. We suppose that these qualities q derive from a broad Gaussian prior:
quality[s] = Variable.GaussianFromMeanAndPrecision(m_q, p_q).ForEach(s);
where the mean of the prior is set to be at the mid-range of the rating levels. The prior parameters are common to all the quality variables (i.e. they sit outside the plate), and so we need ForEach - here shown as an inline expression to indicate they are shared across the s plate. Similarly, we suppose that there is a different amount of noise γ (represented in the code by ‘expertise’) associated with different expertise levels. This noise will affect the observed quality of the review; in fact we would expect that high expertise would lead to more precise reviews - however, we don’t enforce this in the model:
expertise[e] = Variable.GammaFromShapeAndRate(k_e, beta_e).ForEach(e);
k_e and beta_e are shape and rate parameters for the Gamma distribution and are discussed in the paper. Given the quality of the submission and the stated expertise of the reviewer, we derive another variable s which represents the latent score of the review:
score[r] = Variable.GaussianFromMeanAndPrecision(quality[sOf[r]], expertise[eOf[r]]);
Note here that we have used the index maps sOf and eOf that we defined earlier. This completes the right hand side of the factor graph.
The left hand side is a bit trickier. We suppose that the latent score s in the review plate is compared to a number of reviewer-dependent thresholds. The number of thresholds T is set to one less than the number of rating levels, and represent the range of scores corresponding to a particular rating. So a score that is less than the smallest threshold represents the lowest rating (strong reject), a score lying between the lowest and second lowest threshold represents the second lowest rating (weak reject), and so on. We would like to learn these thresholds for each reviewer, to account for how generous or otherwise the reviewer is. A particular reviewer’s set of thresholds will be a noisy version of a standard set of thresholds, where the amount of noise is determined by the accuracy a of the reviewer. The accuracy is a precision much like the expertise precision we discussed earlier and derives from a Gamma distribution with shape and rate parameters k_a and beta_a. The assumption here is that more unbiased reviewers will show less variation away from an ideal set of thresholds given by the nominal thresholds:
accuracy[j] = Variable.GammaFromShapeAndRate(k_a, beta_a).ForEach(j);
theta[j][t] = Variable.GaussianFromMeanAndPrecision(theta0[t], accuracy[j]);
The final step is to incorporate the observed rating for the particular review. To do this, we create a set of bool random variables from logical expressions comparing score with threshold:
observation[t][r] = score[r] > theta[jOf[r]][t]
We can now observe the truth or falsehood of these statements directly from the reviewer’s rating:
// Observations - convert from recommendation to an array of bool
bool[][] obs = new bool[T][];
for (int i=0; i < T; i++)
obs[i] = (from rev in reviews select (i < (int)rev.Recommendation)).ToArray();
observation.ObservedValue = obs;
We can now run inference on this model in the standard way by creating an inference engine and calling Infer. The data is passed to the main Run method as an IEnumerable<Review>; so, for example, you could pass down a List<Review>. The Review class has the following constructor:
public Review(Reviewer reviewer, Submission submission, int recommendation, int expertise)
which you can call to build up your list as you parse your data file.
The KDD 2009 program committee chairs used this model to highlight areas where further screening of submissions was needed, and the model was successful in bringing to light biases in the reviews due to the variation in standards and expertise level of different reviewers. We would love to describe the results in more detail, but unfortunately we cannot due to the confidentiality of the data. One interesting side note is that our expectation, stated earlier, that high expertise should lead to more precise reviews is in fact confirmed by the model which gives precisions of 1.287 (“Informed outsider”), 1.462 (“Knowledgeable”), and 1.574 (“Expert”).
Full code for this model:
The full C# code is in the ReviewerCalibration project.