Learners : Matchbox recommender
Model
The Matchbox recommender in Infer.NET implements the original Matchbox model described in a paper by D. Stern, R. Herbrich, and T. Graepel.
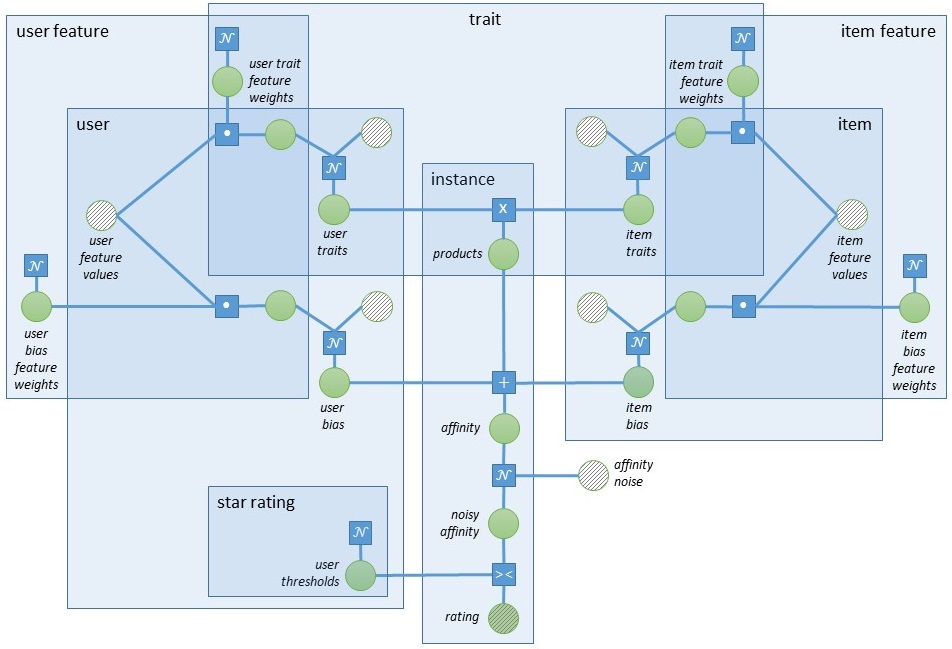
In the core of the model sits the inner product of the user and item traits. Traits can be thought of as implicit features or characteristics learned about the users and the items, such that the observed data can be explained well. More technically, the number of traits is the dimension of the latent space that the users and items are mapped to. An intuition for the concept of traits is given in the Introduction.
The inner product of the user and item traits, plus some added noise, gives an estimation of the affinity between a user and an item. Since Matchbox requires star ratings, this affinity, which is a real number, needs to be mapped to an integer. The way this is achieved is by using a set of rating thresholds for each user. These are learned for each star rating and represent the user-specific boundaries between the ratings. They are needed because different users have different personal definitions of what a given number of stars means. For example, if two users feel equally strongly about a given item, one of them might reinterpret this as 3 stars, while the other one as 4 stars. Then, although the affinity between the two users and the item is the same, the thresholds will allow the model to distinguish between the different number of stars. The Infer.NET code that implements this uses the ConstrainBetween factor to constrain the noisy affinity between the two consecutive thresholds that correspond to the given rating.
All of the user rating thresholds can be offset by a given value - the user bias. This is learned per user and is modelled as a scalar added to the affinity. Note that it is not a part of the user-item trait product, so it is independent of the item. The user bias models the case where some users rate items (on average) higher than other users. Similarly, the model also contains an item bias. It will be high for items that are universally liked, and low for items that are universally disliked.
The model described so far contains the compulsory Matchbox traits, biases and thresholds. We also have a short tutorial explaining how to prototype this in Infer.NET. The original Matchbox model, however, is more complicated than this. It provides support for user and item features. Examples of features include age and gender for the users and movie genre for the items (if we are recommending movies). The presence of features is optional in both cases. That is, the recommender supports scenarios where only user features are available, only item features are available, both of these are available, or neither of them are available. Therefore, they are referred to simply as features in this document.
Features should not be confused with traits. Note that the traits are implicit - you only specify how many there should be, and their values are learned by the model during training. Even if after training we manually examine the values of the traits, it will be difficult to describe in a natural language what exactly they represent. That is because they have been learned by the model such that it can best explain the data. The features, on the other hand, have known values such as user age, user gender, and movie year.
The way features are incorporated in the model is by learning weights for each one of them. That is, the feature model is linear. And unlike the other model parameters, which are learned per user or item, the feature weights are shared across all users or items. This gives the advantage of making improved predictions for users or items which are new to the system (the so-called “cold-start” problem). For example, if profession was a feature in the system, we will probably learn that users whose profession is scientist have a stronger-than-average preference to documentary movies. Then, when a new user comes to the system, and we do not have any prior rating information from them, but we know that their profession is scientist, we can recommend a documentary film.
Feature weights are learned not only per user or item but also per trait. The inner product of the feature weights and feature values serves as an offset to the traits and the bias. Instead of adding the feature influence to the traits and bias , we use it as a prior mean of these parameters. This is implemented in such a way in order to avoid extra symmetries in the model.
A factor graph of the whole model including traits, biases, user thresholds, and features is shown below.