Infer.NET user guide : Learners : Bayes Point Machine classifiers : The Learner API : Mappings
Native Data Format Mapping
The IBayesPointMachineClassifierMapping interface supplies input data in a format that the inference algorithms run by the Bayes Point Machine classifier during training and prediction can consume without any conversion. The supplied format is therefore referred to as the native data format.
The native data format permits two distinct feature representations: dense and sparse. Whereas the dense representation stores all features associated with a single instance in an array of double values, the sparse representation consists of an array of all non-zero feature values and an array of the corresponding feature indices. Both representations produce the same results, only at different computational costs. Training and prediction on data with many zero-valued features is typically faster in a sparse representation.
In addition to the features representations, the native format also fixes the type of the labels. In binary classification, labels must be Boolean, in multi-class classification labels must be provided as zero-based, consecutive integers (i.e. 0,1,…,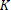 - 1, where is the number of classes).
- 1, where is the number of classes).
Delivering data in native format requires an implementation of 8 methods:
-
IsSparse:
bool IsSparse(TInstanceSource instanceSource);IsSparseindicates whether the features are specified in a sparse or a dense representation. Note that the feature representation must not be changed. Neither between instances nor between different instances subsets, such as training and test sets. -
GetFeatureCount:
int GetFeatureCount(TInstanceSource instanceSource);GetFeatureCountstates how many features the classification data contains. It is needed to set up the inference algorithms (it determines the number of weights, for instance) when the features have a sparse representation (as one cannot infer the total number of features in this representation). -
GetClassCount:
int GetClassCount( TInstanceSource instanceSource = default(TInstanceSource), TLabelSource labelSource = default(TLabelSource));GetClassCountreturns the total number of class labels present in instances.
All aforementioned three methods are used to set up the Bayes Point Machine classifier and verify the validity of both features and labels. They are called during training as well as prediction. IsSparse and GetFeatureCount partially determine the expected return values of GetFeatureValues and GetFeatureIndexes (see below).
The next two methods deliver feature values and indices for single instances and are only used during singleton prediction. Their return values will not be cached.
-
GetFeatureValues (single-instance):
double[] GetFeatureValues( TInstance instance, TInstanceSource instanceSource = default(TInstanceSource));GetFeatureValuesreturns an array of feature values for the specified instance. If the feature representation is sparse (i.e.IsSparsereturns true), this method only returns all non-zero feature values associated with the given instance. If the representation is dense,GetFeatureValuesreturns all feature values whether they’re zero or not. -
GetFeatureIndexes (single-instance):
int[] GetFeatureIndexes( TInstance instance, TInstanceSource instanceSource = default(TInstanceSource));GetFeatureIndexes returns null if features are expected to be in a dense representation. Otherwise it returns an array of feature indices corresponding to the non-zero feature values returned by the single-instance GetFeatureValues method.
Then, there are two methods which provide feature values and indices of multiple instances to both the training and prediction algorithms. During training, the set of instances may be further split into subsets, referred to as batches, which makes it possible to learn from data that does not fit into memory (more on this in Batched training). Bulk prediction, which also calls into the following two methods, does not work with batches.
-
GetFeatureValues (multi-instance):
double[][] GetFeatureValues( TInstanceSource instanceSource, int batchNumber = 0);GetFeatureValuesreturns an array of feature values for each instance associated with the specified batch of instances. By default, it is assumed that the features and labels of all instances may live in a single batch. If this is not possible, perhaps because this requires too much memory, the Bayes Point Machine classifier mapping allows to split the training data into a number of batches (specified by the Bayes Point Machine classifier settingBatchCount). Instance batch indexes run from 0 toBatchCount- 1. Note also that a single training run passes several times over the all batches (seeIterationCountsetting).Again, the feature representation may be sparse or dense, dependent on the return value of
IsSparse. -
GetFeatureIndexes (multi-instance):
int[][] GetFeatureIndexes( TInstanceSource instanceSource, int batchNumber = 0);GetFeatureIndexesreturns null if features are expected to be in a dense representation. Otherwise it returns the feature indices of all instances in the specified batch of instances. These must correspond with the feature values returned byGetFeatureValues, given the same batch of instances.
The final method in IBayesPointMachineClassifierMapping provides ground truth labels during training:
-
GetLabels:
TLabel[] GetLabels( TInstanceSource instanceSource, TLabelSource labelSource = default(TLabelSource), int batchNumber = 0);GetLabelsprovides all ground truth labels for a given batch of instances from an instance or label source. Note thatTLabelis bound toboolin binary classification and tointin multi-class classification.GetLabelsis not called during prediction.
The NativeClassifierMapping class and its subclasses in the Microsoft.ML.Probabilistic.Learners.BayesPointMachineClassifierInternal namespace are examples of implementations of the IBayesPointMachineClassifierMapping interface. These classes wrap IClassifierMapping and show how data in standard format is converted to native format. They also show how to cache data batches during training.